本文由 @NGDCN 于2022-11-25发布在 未来网络技术网,如有疑问,请联系我们(ngdcn_admin@163.com)。
热门文章

【Infiniband手册】第9章:传输层
2022-10-27
【推荐】计算机网络顶级会议:快速检索目录
2022-11-07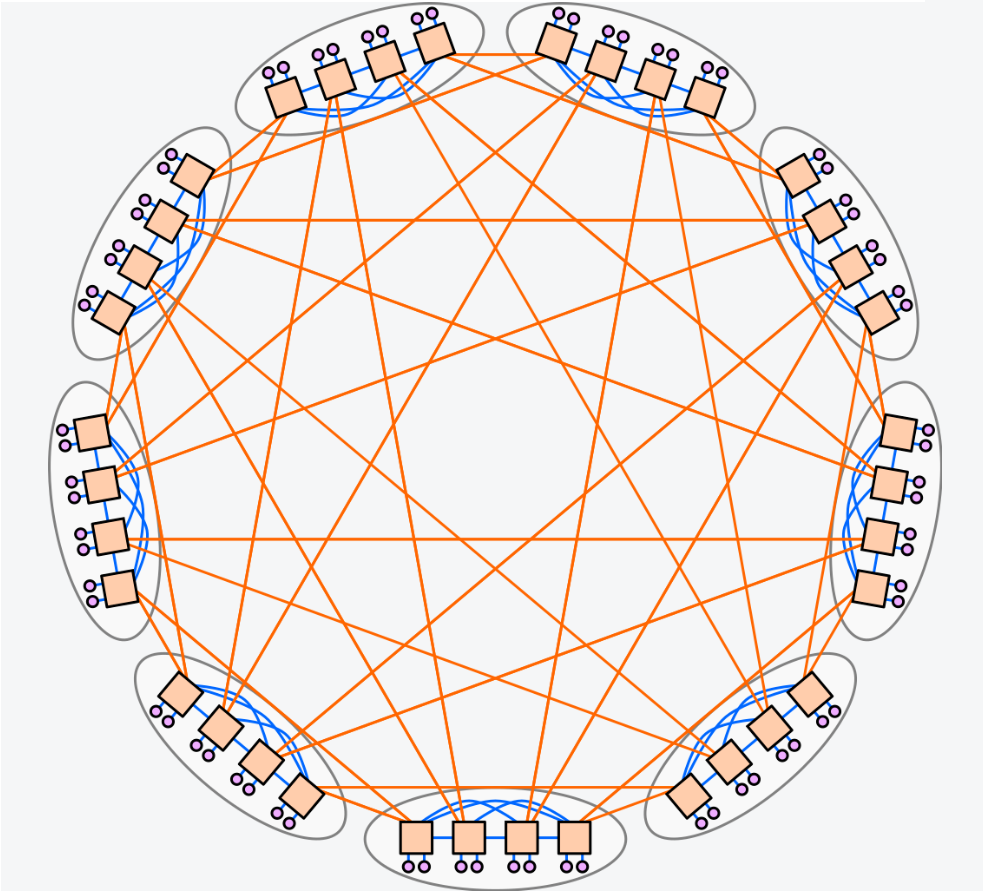
一文读懂Dragonfly拓扑
2023-02-24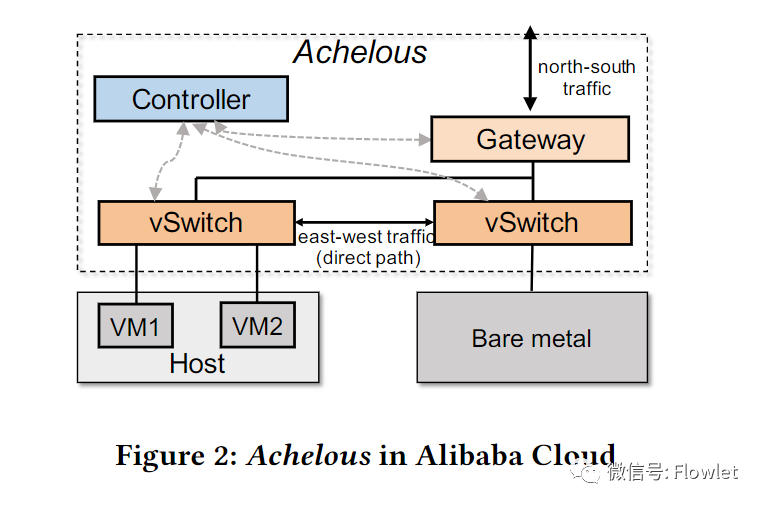
【Sigcomm 2023】 Achelous:超大规模云网络中如何实现网络的可编程性、弹性和可靠性
2023-10-06
Alibaba高性能通信库ACCL介绍
2023-02-21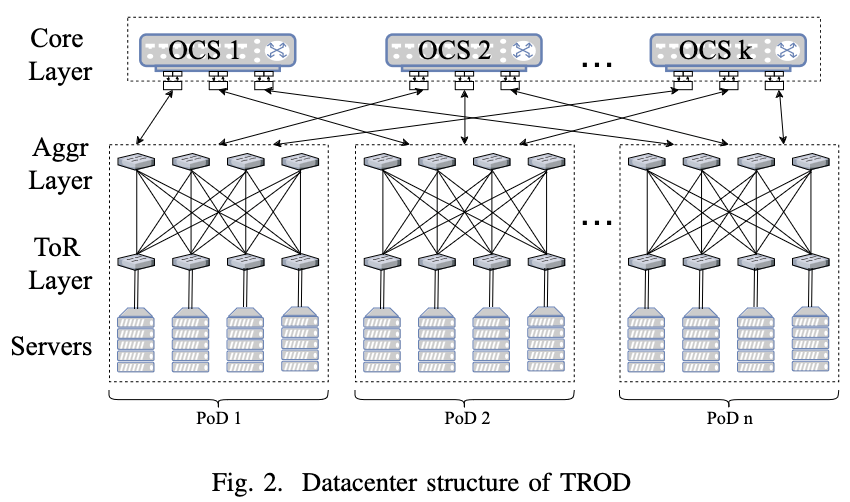
【ICNP 2021】怒赞!上海交大团队先于谷歌提出光电混合数据中心慢切换方案
2023-05-10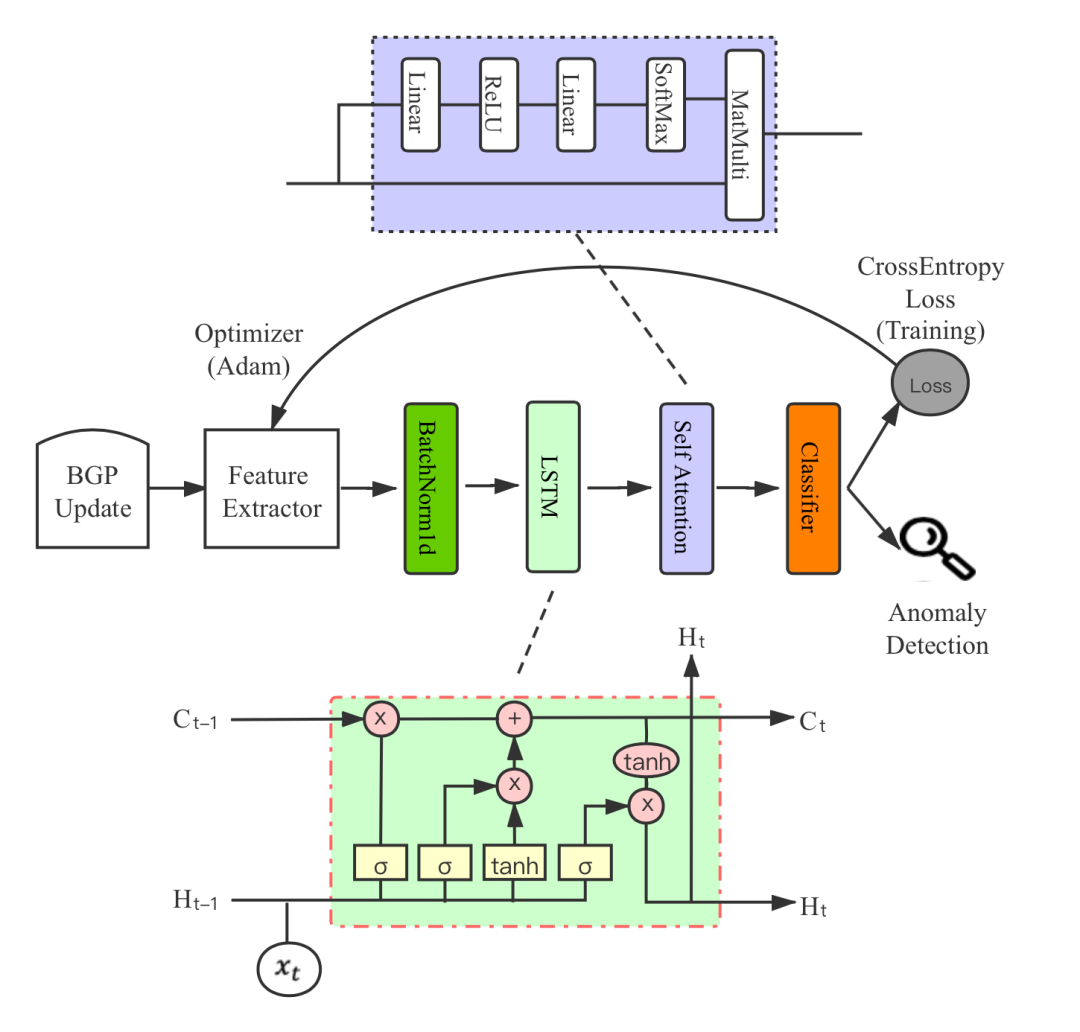
【ICNP 2021】基于弱监督学习的ISP自助BGP异常检测
2023-05-10
【微软】MSCCL Github仓库介绍
2023-02-20
有话要说...