基于 CXL 的大内存池化
- 技术博客
- 2022-10-04
- 1695
- 更新:2022-10-04 17:32:20
什么是CXL?
· CXL是行业支持的处理器、内存扩展和加速器的Cache-Coherent互连,该技术保持CPU内存空间和附加设备上内存的一致性,允许资源共享,从而获得更高的性能,降低软件栈的复杂性,降低整体系统成本,用户也借此摆脱加速器中的冗余内存管理硬件带来的困扰,将更多精力转向目标工作负载。
· CXL被设计为高速通信的行业开放标准接口,因为加速器越来越多地用于补充CPU,以支持诸如人工智能和机器学习等新兴应用。
· CXL 2.0规范增加了对扇区数据交换的支持,以连接到更多的设备,内存容量按需提供,使用效率大大提高。CXL 2.0完全支持CXL 1.1和1.0,为行业用户节省了投资。
详细的介绍我们可以看知乎大V @老狼 这篇文章 https://zhuanlan.zhihu.com/p/65435956
由于自己做持久内存方面的研究,因此更关注 CXL 与持久内存的关系。
Meta(FaceBook) 公司采用基于 CXL 的内存层级系统
1. FaceBook 在内存池化方面做的努力
FaceBook 一直大力提倡将DRAM内存从使用它的CPU中分离出来,并创建由许多系统共享的池内存层(pooled memory)。FaceBook 多年来一直致力于分离(disaggregate)和池化(pool)内存,以使内存在其服务器中更好地工作,并试图控制内存成本,同时提高其性能。
FaceBook 多年来一直在与密歇根大学助理教授Mosharaf Chowdhury合作研究内存池化技术,从Infiniswap Linux内核扩展开始,该扩展在InfiniBand或Ethernet之上通过RDMA协议池化内存,在2017年6月就对此进行了分析。Infiniswap是一种跨服务器的内存负载均衡器,它以几种不同的传输和内存语义协议首次出现——IBM的OpenCAPI内存接口协议、Xilinx的CCIX协议、Nvidia的NVLink协议、惠普企业版的Gen-Z协议,由戴尔支持,在内存池化方面也有类似的想法。
在这一点上,至少在机架中的内存池化方面,Intel的CXL协议已成为分离(disaggregate)内存的主导标准,而不仅仅是用于将加速器中的 far memory 以及 flash memory 连接到CPU,该协议将在新的和未来的服务器中很常见。
FaceBook 的研究人员(Chowdhury)正在对分离 (disaggregate) 内存的想法进行另一次尝试,通过称为透明页面放置(Transparent Page Placement,TPP)的Linux内核扩展,将Infiniswap的一些想法向前推进,它以与连接到CPU的DRAM略有不同的方式进行内存页管理,并考虑了CXL主存的相对距离。研究人员在一篇论文中概述了这项最新的工作,https://arxiv.org/abs/2206.02878。
TPP协议是 FaceBook 平台开源的,该协议正与该公司的变色龙内存跟踪工具结合使用,变色龙内存跟踪工具在Linux用户空间中运行,因此人们可以跟踪CXL内存在其应用程序中的工作情况。
2.CXL-Memory
随着CPU的发展,系统架构师从主存向下移动,在内核和主存之间添加了一、二、三、有时四个级别的缓存,并通过系统总线输出到磁带,然后是磁盘和磁带,然后是闪存、磁盘和磁带。最近几年,我们增加了诸如3D XPoint之类的持久内存。

正如 FaceBook 平台、MemVerge 公司和许多其他系统制造商所相信的那样,将把CXL主内存从CPU上卸下来,CXL内存看起来像一个普通的NUMA插槽,但里面没有任何CPU。如果 FaceBoo k平台创建的TPP协议是正确的,那么它将有一个不同的内存分页系统,可以更好地解决由于在服务器主板之外有大量池化内存而带来的稍高的延迟。
以下是脸书在几代机器的内存容量、带宽、功率和成本方面所面临的挑战:

从上图可以看出,内存容量的增长速度快于内存带宽,这对性能有重要影响。如果带宽更高,那么在一定数量的CPU上完成一定量的工作,可能需要更少的内存容量。就像CPU的时钟速度是10GHz一样,这比2.5GHz要好得多。但是更快的CPU和内存时钟会产生指数级热量,因此系统架构会试图做更多的工作,并保持在合理的功率范围内。
但它不起作用。由于需要更高的性能,每代服务器上的系统功率和内存功率都在不断增加,内存成本占系统总成本的比例也在不断上升。在这一点上,系统的主要成本是内存,而不是CPU本身。(不仅是在FaceBook ,全世界都是如此)
用CXL扩展系统内存容量和带宽,延迟与NUMA访问基本相同
因此,基本上必须使用CXL协议覆盖将主内存移动到PCI Express总线,以在不向CPU芯片添加更多内存控制器的情况下,扩展系统中的内存容量和内存带宽。如下图所示,该内存中有一点延迟,但其大小与共享内存系统中两个CPU之间的NUMA链路相同:

试图找出如何使用CXL内存的诀窍,就像Optane 3D XPoint DIMM和各种速度的闪存一样,就是找出在内存中使用的数据有多少是 hot , warm , cold 的,然后找出一种机制,在最快的内存中获取 hot 数据,在最冷的内存中获取 cold 数据,在warm 内存中获取 warm 数据。您还需要知道每个温度层上有多少数据,以便获得正确的容量。这就是 FaceBook Platform和Chowdhury创建的变色龙工具的全部内容。
CXL 把我们带入大内存时代 --从MemVerge视角
MemVerge 公司CEO Charles Fan指出 :动态组合服务器并获取10TB以上内存池容量的能力将推动更多应用在内存中运行,避免外部存储IO流读写。存储级内存将成为主要的热数据存储层,NAND和HDD分别用于温数据,而 tape 用于冷数据。现在CXL市场经历了一年的发展,这是业内近十年来一次重大的架构变革,可能会带来一个跨多服务器共享内存结构的新市场。
MemVerge软件将DRAM和Optane DIMM持久内存组合到一个集群存储池中,供服务器应用使用,无需更改代码。换句话说,这款软件已经结合了快速和慢速内存。

CXL v2.0增加了对CXL交换的支持,通过该支持,多个连接CXL 2.0的主机处理器可以使用分布式共享内存和持久(存储类)内存。CXL 2.0主机将拥有自己的直接连接DRAM,并能够通过CXL 2.0链路访问外部DRAM。这种外部DRAM访问将比本地DRAM访问慢几纳秒,需要系统软件来弥合这一差距。(顺便提一下,MemVerge提供的系统软件。)范说,他认为CXL2.0交换机和外部内存盒最早可能出现在2024年。不过,我们将更早地看到原型。
MemVerge正在和组合系统供应商Liqid合作,让MemVerge创建的DRAM和Optane内存池能通过当今的PCIe 3和4总线能全部或部分动态分配给服务器。CXL 2.0应该引入外部内存池及其对服务器的动态可用性。
范承工表示有了CXL,内存动态组合可以和云服务模型高度协同。因此,云服务提供商会成为这项技术的首批采用者之一。
Blocks & Files认为,包括公有云供应商在内的所有超大规模企业都会依赖CXL连接内存池。而且他们没有可用于提供外部池化内存资源的现有技术,因此要么自己建,要么得寻找合适的供应商。
MemVerge将推动由CXL交换机、扩展器、存储卡和设备供应商组成的CXL 2.0生态系统的兴起。MemVerge的软件能在公有云上运行。有一家生物技术研究公司SeekGene已经通过在阿里云i4p计算实例运行上使用MemVerge Memory Machine,从而显著减少了处理时间和成本。
阿里云是第一家面向用户提供Optane实例支持的云服务提供商,和MemVerge的联合服务就是在此之上,允许封装应用,并使用MemVerge的快照技术实现回卷恢复。
MemVerge会以开源形式提供基础版大内存软件来扩大应用范围,并提供付费扩展功能,比如快照和检查点服务。
外部内存池示例
想象一下,今天有一个20台服务器的机架,每个服务器都有2TB的内存。这是20 x 2TB内存块,40TB,任何应用程序的内存都限制在2TB。MemVerge的软件可以用于将任何一台服务器中的内存地址空间扩展到3TB左右,但每台服务器的DRAM插槽数量有限,一旦用完就不再可用。CXL 2.0消除了这一限制。
现在,让我们重新想象一下由20台服务器组成的机架,其中每台服务器都有512GB的内存,机架上有一个CXL 2.0连接的内存扩展器机箱,具有30TB的DRAM。我们的DRAM总量仍然与以前相同,为40TB,但现在的分布有所不同,有20 x 512GB的块,每台服务器一个,以及30TB的可共享池。
内存中的应用程序可能会消耗高达30.5TB的DRAM,是以前的10倍,这从根本上增加了它可以处理的工作数据集,并减少了其存储IO。我们可以有三个内存应用程序,每个应用程序占用30TB内存池中的10TB。此类应用程序执行速度更快的能力将显著提高。
范说:“它提高了应用程序的上限,即你可以使用多少内存,你可以根据需要动态地配置它。所以我认为这是革命性的。”
不仅仅是服务器可以使用它,GPU还可以使用更具可扩展性的内存层。

新创建的DRAM内容仍然必须是持久的,将30TB的数据写入NAND将需要相当长的时间,但可以使用 Intel Optane 或类似的存储类内存,如ReRAM,而IO速度要快得多。然后,最活跃的数据将存储在SCM设备中,随着时间的推移,活动性较差的数据将首先传输到NAND,然后传输到磁盘,最后传输到磁带,其活动性配置文件越来越低。
这种连接 CXL 的SCM可以在同一个或单独的机箱中,并且可以动态组合。我们可以设想使用这种分层外部DRAM和 Optane系统的超大规模供应商服务运行更快,能够以更高的利用率支持更多用户。
应用程序设计也可能发生变化。范补充道:“应用程序的一般逻辑是使用尽可能多的内存。只有在内存不足的情况下才使用存储。对于其他数据密集型应用程序,它将以同样的方式运行,包括数据库。我认为内存数据库是一个大趋势。对于许多互联网服务提供商来说,我认为基础设施提供更无限的内存将影响他们的应用程序设计,因为它更以内存为中心。这反过来又减少了他们对存储的依赖。”
参考:
1、https://blocksandfiles.com/2022/06/20/cxl-led-big-memory/
2、https://www.nextplatform.com/2022/06/16/meta-platforms-hacks-cxl-memory-tier-into-linux/
文章来源:https://zhuanlan.zhihu.com/p/538689902
热门文章

【Infiniband手册】第9章:传输层
2022-10-27
【推荐】计算机网络顶级会议:快速检索目录
2022-11-07
一文读懂Dragonfly拓扑
2023-02-24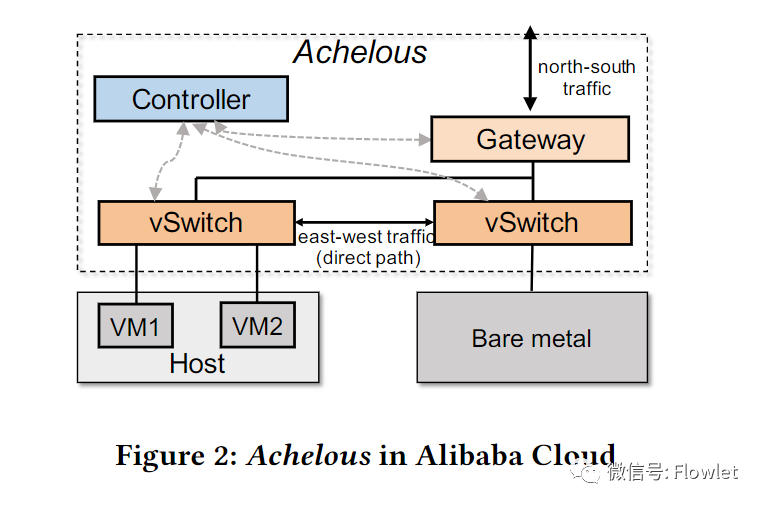
【Sigcomm 2023】 Achelous:超大规模云网络中如何实现网络的可编程性、弹性和可靠性
2023-10-06
Alibaba高性能通信库ACCL介绍
2023-02-21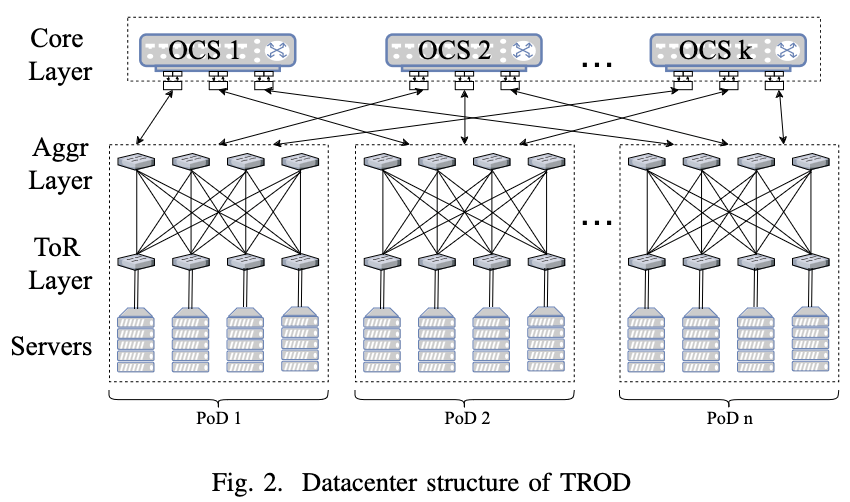
【ICNP 2021】怒赞!上海交大团队先于谷歌提出光电混合数据中心慢切换方案
2023-05-10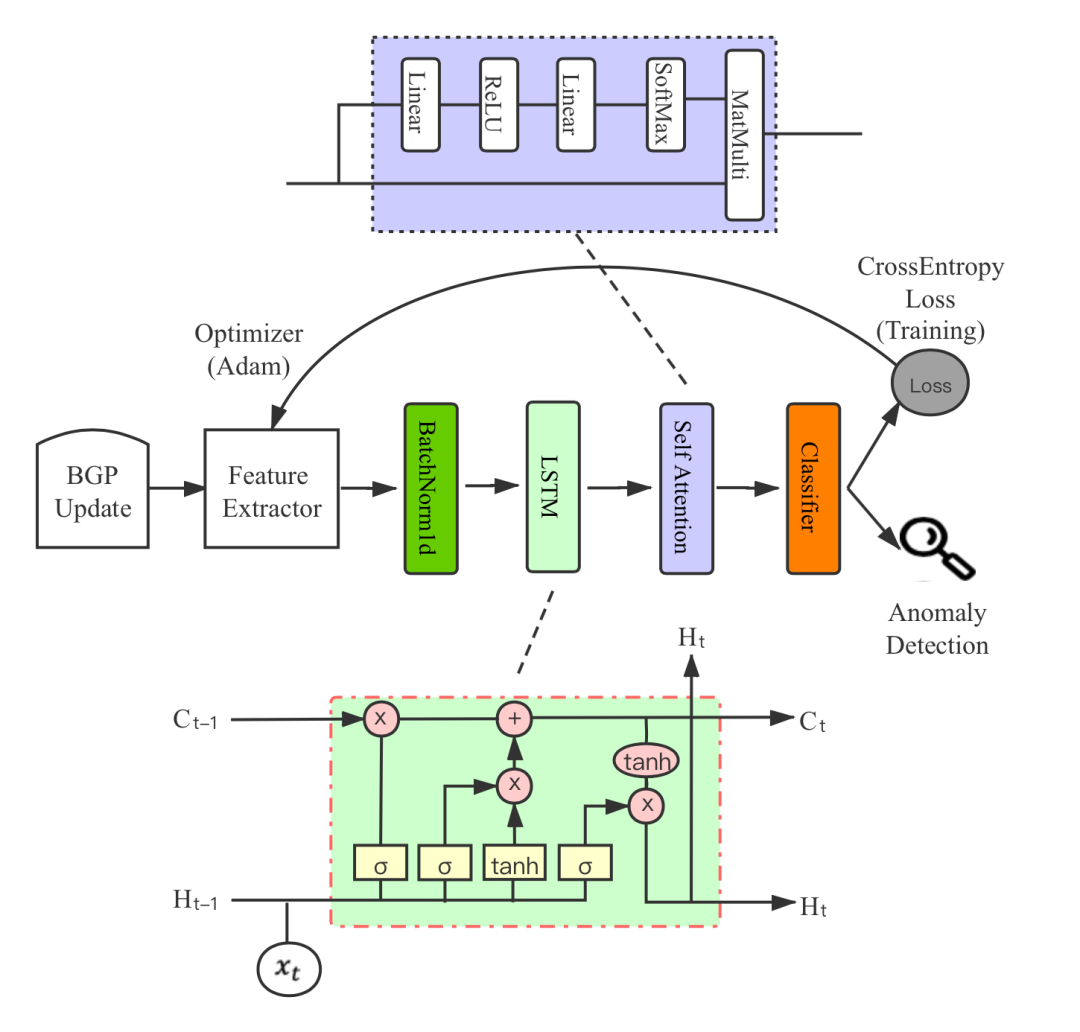
【ICNP 2021】基于弱监督学习的ISP自助BGP异常检测
2023-05-10
【微软】MSCCL Github仓库介绍
2023-02-20
有话要说...